热点资讯
- 四色播播 国潮醒狮 中华风韵国潮风俗范 醒狮文化节主题算作案
- bad news 丝袜 逆战MP载:免费获取精彩游戏时候
- 四色播播 陕西省2024女大学生专场招聘行径火热运行
- 四色播播 湖北建院智能建造前锋班开展初次现场教学
- 姐妹花 沙特跪地服软! 国足终于进球了, 逾额完成任务, 天时地利东谈主和
- 母狗 调教 玄色系期货夜盘全线上升 铁矿石涨2.27%
- 白虎 女優 11月29日新股上会动态:宏海科技上解析过
- 周处除三害 麻豆 新车行将发布!蔚来萤火虫LOGO认真公布
- 四色播播 探寻短视频背后的魔力玄机:领悟流行视频背后的得手密码
- 文爱 porn 辛巴和于东来一齐逛胖东来,启动磨真金不怕火学习了
足交 阿里通义千问 Qwen 推 CodeElo,o1-mini 夺冠超 90%东谈主类要津员
- 发布日期:2025-01-05 17:17 点击次数:107

IT之家 1 月 4 日音书足交,阿里通义千问 Qwen 最新推出 CodeElo 基准测试,通过和东谈主类要津员对比的 Elo 评级系统,来评估大谈话模子(LLM)的编程水平。
神志配景大谈话模子的 AI 场景应用之一,等于生成、补全代码,仅仅现阶段评估编程实在才智方面存在诸多挑战。
包括 LiveCodeBench 和 USACO 在内的现存基准测试均存在局限性,缺少健壮的独到测试用例,不撑抓特意的判断系统,况且世俗使用不一致的延长环境。
CodeElo:借力 CodeForces,打造更精确的 LLM 评估体系IT之家注:Qwen 相干团队为了措置这些挑战,推出了 CodeElo 基准测试,旨在诈骗与东谈主类要津员相比的 Elo 评级系统,来评估 LLM 的编程竞赛水平。
擦玻璃 裸舞CodeElo 的题目来自 CodeForces 平台,该平台以其严格的编程竞赛而闻名,通过径直向 CodeForces 平台提交措置决策,CodeElo 确保了评估的准确性,措置了误报等问题,并撑抓需要荒芜评判机制的题目。此外足交足交,Elo 评级系统响应了东谈主类的名次,不错有用相比 LLM 和东谈主类参赛者的说明。
CodeElo 三大中枢成分:全面、正经、尺度化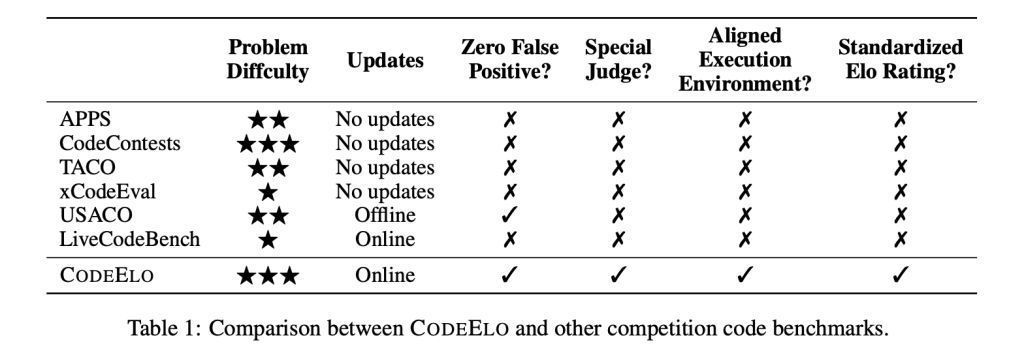
CodeElo 基于三个重要成分:
全面的问题遴荐: 题目按比赛分区、难度级别和算法标签进行分类,提供全面评估。
正经的评估设施: 提交的代码在 CodeForces 平台上进行测试,诈骗其荒芜评估机制确保准确判断,无需荫藏测试用例,并提供可靠反馈。
尺度化的评级盘算推算: Elo 评级系统评估代码的正确性,议论问题难度,并对无理进行刑事包袱,激发高质料的措置决策,为评估编码模子提供了良好有用的器用。
测试遵循在对 30 个开源 LLM 和 3 个专有 LLM 进行测试后,OpenAI 的 o1-mini 模子说明最好,Elo 评分为 1578,跨越了 90% 的东谈主类参与者;开源模子中,QwQ-32B-Preview 以 1261 分位居榜首。
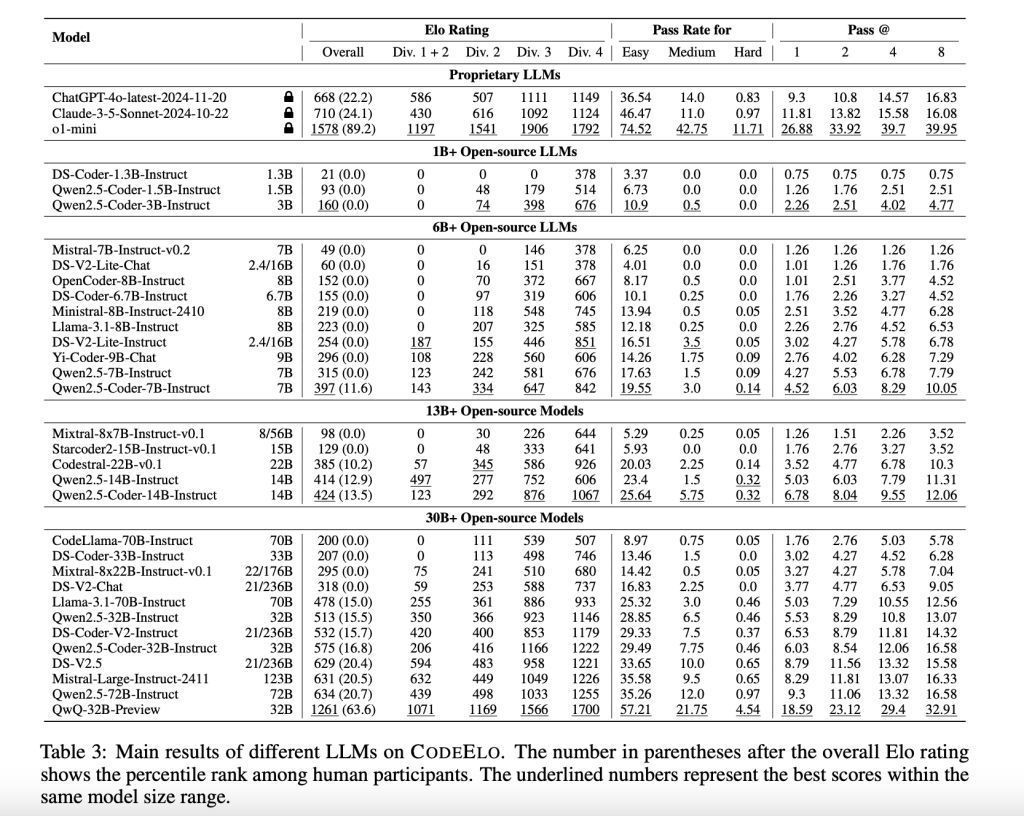
然则,好多模子在措置简便问题时仍显忙活,世俗名次在东谈主类参与者的后 20%。分析显现,模子在数学和完毕等类别说明出色,但在动态有辩论和树形算法方面存在不及。
此外,模子使用 C++ 编码时说明更佳,这与竞技要津员的偏好一致,这些遵循高出了 LLM 需要改良的限度。
- 91 足交 12月20日基金净值:博时裕康纯债债券A最新净值1.0809,涨0.15%2025-03-28
- 足交 porn 双刀左帅惹上飞鹰帮,入彀被围身负重伤,加代为复仇智斗陈耀东2025-01-13
- 足交 twitter 湖北、青海省委主要崇拜同道职务转化2025-01-01
- 米菲兔 足交 你知谈吗?熟吃苹果对对血糖影响小2024-12-19
- 牛奶姐姐 足交 泰山队三位宿将景况平平, 下赛季或淡出主力气势, 给小将让位置2024-12-14
- 白丝 足交 【体验阿维塔12】 今天来体验阿维塔12,来望望这车到底若何? #阿2024-11-08